
> Kaggle에서 다운받은 Titanic Data Set 업로드
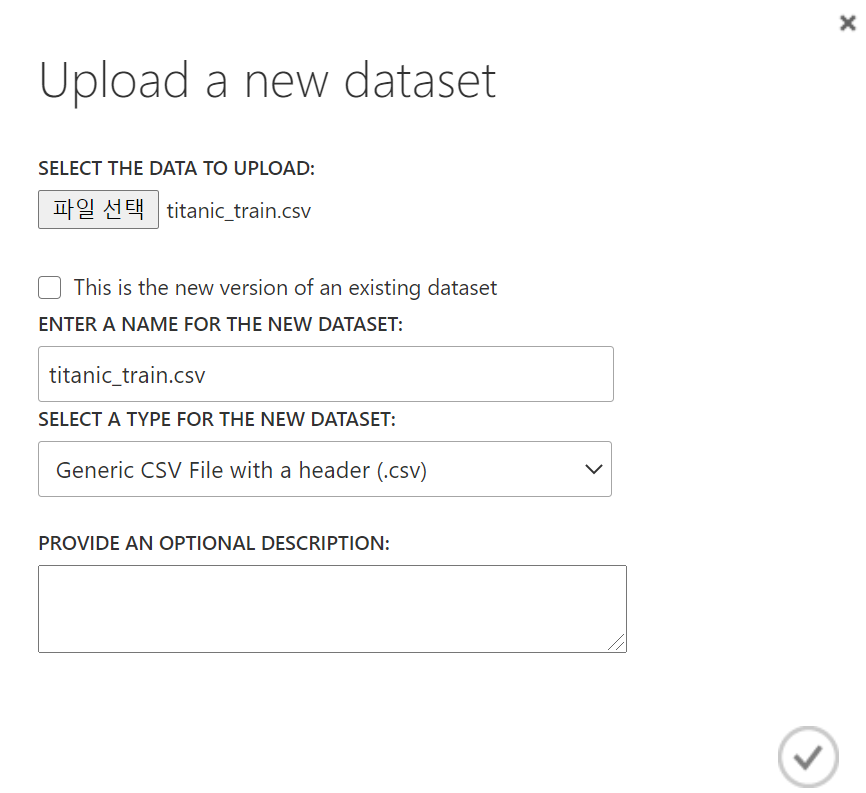
> New Experiment - Data Set 불러오기

> 필요한 컬럼만 선택
모듈 추가
👇
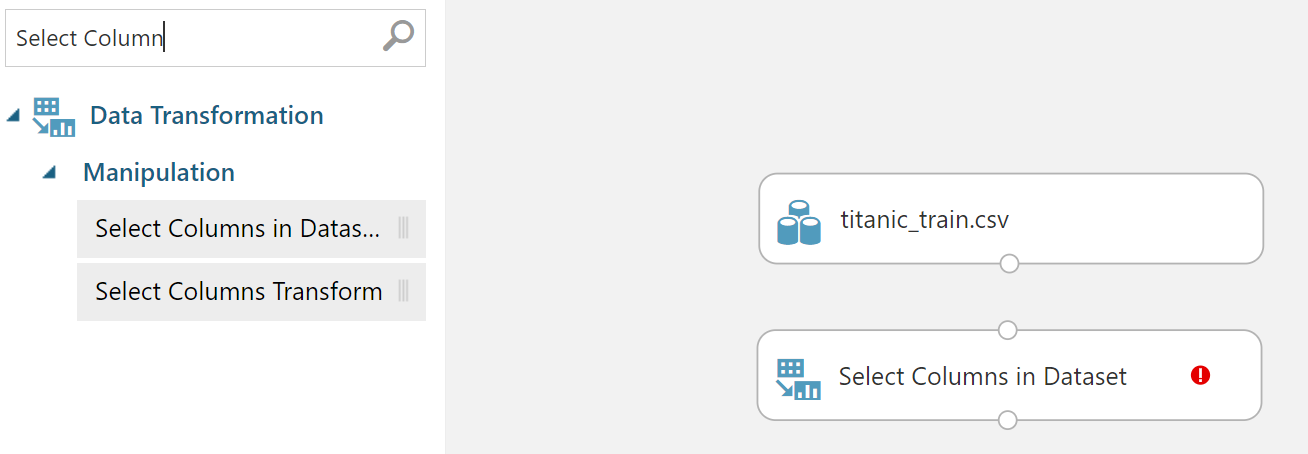
컬럼 선택
👇

컬럼 필터링 확인
👇

> Survived 생존여부 컬럼이 숫자로 인식되면 안됨,
생존여부 유 무로만 분류될 수 있게 Boolean 타입으로 바꾸어야 함

Edit Metadata 모듈 추가
👇

Edit 하려는 컬럼(Survived) 선택 및 Data Type - Boolean으로 설정
👇


Run 하여 적용시킨 다음 Vizualize를 통해 확인
👇

> Missing Value 해결
빠진 값이 있는 행을 아예 삭제하기도 하지만,
데이터 양이 너무 없어서 이거라도 살려야 싶을 때
데이터의 평균값을 그 값에 채워주는 최후의 방법도 있다.

Clean Missing Data 모듈 추가
👇

Missing Value 처리할 컬럼 선택
👇

Missing Value처리 방식 선택 : Remove Entire Row
👇

Run 하여 적용시킨 다음 Vizualize를 통해 확인
👇

> 모델 테스트할 알고리즘 선택 : Predicting Categories - Two-Class

알고리즘을 포함하여 Train/Score/Evaulate Model 모듈 추가
👇

Data 분리 분포 설정(8:2)
👇

Train Model에서 예측하고자 하는 컬럼 선택
👇

Run 하여 적용시킨 다음 Score Model-Vizualize를 통해 확인
👇

Run 하여 적용시킨 다음 Evaluate Model-Vizualize를 통해 확인
👇

> 두번째 알고리즘 추가
Two Class Decision Forest 알고리즘 모듈을
추가한 다음 위의 방식과 똑같이 수행하여 알고리즘 모델 결과를 비교

Run 하여 적용시킨 다음 Evaluate Model-Vizualize를 통해 확인
👇


Azure automatic ml: 머신러닝을 돌려주는 머신러닝
제일 좋은 알고리즘을 찾아주는 머신러닝(Parameter 조정까지 !!!)
" All models are wrong, but some are useful "
모델들이 어떠한 데이터 셋에 딱 들어맞는 것은 좋지 않다
데이터는 유동적이기 때문에 특정한 데이터에만 들어맞는 경우 새롭게 들어오는 데이터에는
맞지 않는 모델이 되기 때문이다.
'자기발전소 > # Machine Learning' 카테고리의 다른 글
| Azure ML Studio 실습: Walmart 판매액 예측 모델 (0) | 2020.12.28 |
|---|---|
| OCR(Optical Character Recognition) 실습 (0) | 2020.12.24 |
| Face Recognition 실습 (0) | 2020.12.24 |
| Computer Vision API 실습: Object Detection (0) | 2020.12.24 |
| Cognitive Services (0) | 2020.12.24 |



